Wednesday, November 17, 2010
Let's explore the core of the platform
Here are some relevant points about the filesystem
- Scales linearly over a set of low-budget comodity machines, doubled the amount of machines = reduced the processing time to half
- Tolerates faults at different levels, from network, switches, disks, nodes, readdressing data traffic to other nodes, accomplishing a replica factor
- Flexible scalability, for maintenance tasks, you only have to dis/connect computers into the rack
- Lets you allocate any kind of files and formats, although it has better performance on files bigger than 128mb
- The results of MapReduce jobs are stored in the filesystem
- There's a unique namespace, with an automatic replication schema administered by the master, it's not possible to impact on a certain node in the cluster, whether to allocate files or execute jobs
- The master itself balances the workload over execution plans and status reports from the slave nodes
(Click to enlarge)

{kind=link}
- Has a mechanism of continuous replication per file, rack-aware, to extend data reliability and data availability warranties
- Has an automatic file checksum with inmediate correction
- Works in a master-slave schema where slaves share nothing between them, they only respond to master requests
- The master coordinates all types of transactions, read/write, replication, restore, manages the tx log and the filesystem namespace
- The slaves only take charge on low level operations over data, read, write, deletion, transport to-from client
Main characteristics of Map Reduce
- It's a processing model about dividing and distributing information, in two chained phases: map first, then reduce
- Both phases have as input and output, a key-value pair list,
- The schema allows to define method parameters and own logic for both phases, as well as their own partitioning system and intermediate storage between phases.
- The transactions are handled by a JobTracker daemon, that runs the initial data partitioning and the intermediate data combination, by posting tasks of type Map and type Reduce over the TaskTracker daemons (1-n x computer) of the nodes involved in the cluster, according the data being processed
- the Reduce phase only starts when finished the Map, cause after the Map the resulting keys are combined, to distribute a sorted list of key-value pairs between the Reducers, that can be matched at the end of them.
- The process is transactional, those map or reduce tasks not executed, (for data availability issues) will be reattempted a number of times, and then redistributed to other nodes.
(Click to enlarge)
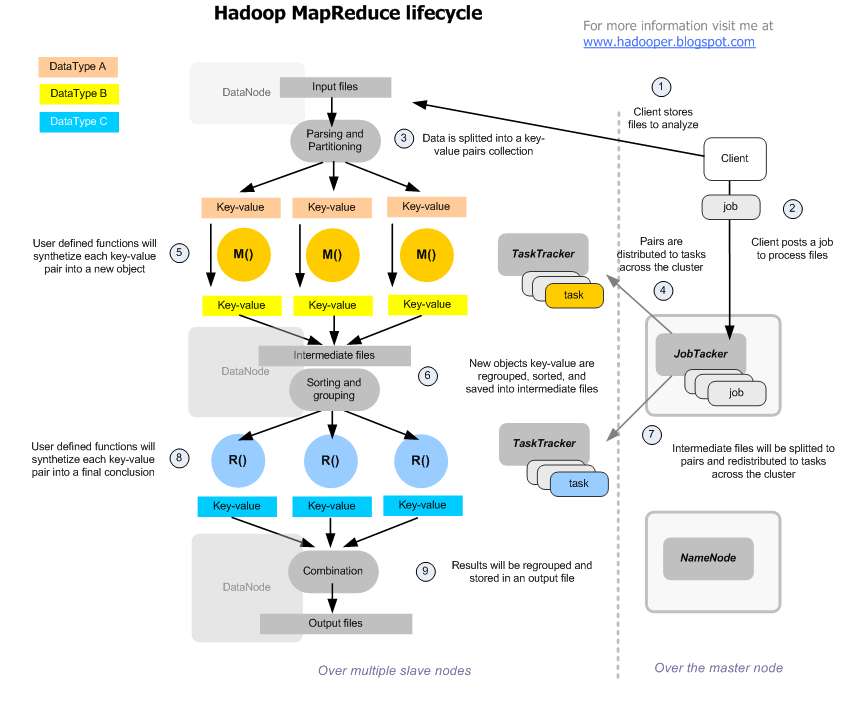
- First the files are partitioned in parts that will be distributed to process across the cluster nodes
- Each part is parsed in pairs of Key(sorteable object) - Value(object), that will be the input parameters for the tasks implementing the Map function
- These user defined tasks (map), will read the value object, do something with it, and then build a new key-value list that will be stored by the framework, in intermediate files.
- Once all the map tasks are finished, it means that the whole data to process was completely read, and reordered into this mapreduce model of key-value paris.
- These intermediate key-value results are combined, resulting a new paris of key-value that will be the input for the next reduce tasks
- These user defined tasks (reduce), will read the value object, do something with it, and then produce the 3rd and last list of key-value pairs, that the framework will combine, and regroup into a final result.
Let's see a sample job with a reverted-index function, for analyzing the webcrawler's output files (just for instance)
(Click to enlarge)

{kind=link}
Tuesday, November 2, 2010
For the newcomers, I'll provide here a simple approach to understand Hadoop's design and main goals.
Compare: one of the first mistaken attitudes !
A typical transaction system lives inside the range of some gigabytes data, in random access. It runs inside an application server, acceses and takes control over a relational database allocated in a different server, transporting data in and out of it.
Interacts with online clients, keeping a reduced size of data in transport, with a shared and limited bandwith, the operations are most of all continuous reading over small sets of data, combined with some maintenance & CRUD operations.
Bigger data processing is done in batch, but the architecture is the same.
But a different scenario ?
What happens if we need to process 1 petabyte/week ?, let's say a much lesser size, 1 terabyte/day, less, 100 gigabytes/day
Under the traditional schema, it would be like moving an elephant over a string thousands of times, the time-windows would not allow to work with realtime information, but always trying to keep up and losing the race.
Want problems ?
The network would saturate, batch processes would take days to finish information of hours, the harddisk latency access it will transform into an incremental overhead, having a painful impact on overall costs.
The traditional approach would mantain the architecture, but changing hardware, sophisticated requirements, each time more expensive, bigger, but over a limited growth architecture. How many times will you change your system's architecture to non-linear scalar solutions to keep up with the race of growing data, ?
The solution is in the focus !
Problem 1: Size of data
systems handling public data, can have huge processing flows with hundreds of terabytes, public websites have had increased their data up to petabytes !
Strategy 1: Distribute and paralellize the processing
If chewing 200 Tb of data takes 11 days in 1 computer, let divide the whole process into as many machines needed to finish the task in minutes or hours !
If we'll have lot of computers, so be they cheap and easily mantained !, into a simple add & replace node architecture.
Problem 2: Continuous failure and cluster growth
In a big cluster, lot of machines fail everyday, besides the cluster size cannot be fixed and sometimes cannot be planned, it should grow easily at the speed of data.
Strategy 2: High fault tolerance and high scalability
Any design must have an excelent fault-tolerance mechanism, a very flexible maintenance, and its service availability should keep up naturally to its cluster size.
So we need a distributed storage, atomic, transactional, with perfect linear scalability.
Problem 3: Exponential overhead in data transport
From data source to its processing location, bad harddisk latency and saturated networks will end up exploting
Strategy 3: Move application logic to data storage
It must allow to handle data and processes separately and in a transparent way, applications should take care of their own business application code, and the platform should automatically deploy it into the datastorage, execute and handle their results,
So...
One Solution: Hadoop Distributed Filesystem + Hadoop MapReduce
Anyway, Hadoop is not bullet-proof, actually, it's a very specific solution for some big-data scenarios, with needs of realtime processing, and technology choices for random access to data. (See HBase, Hive)
Hadoop is not designed to replace RDBMS, but instead, has been proven to handle -in a much performant way- huge amounts of data, whereas traditional enterprise database clusters, wouldn't work not even close at the same overall costs !
Compare: one of the first mistaken attitudes !
A typical transaction system lives inside the range of some gigabytes data, in random access. It runs inside an application server, acceses and takes control over a relational database allocated in a different server, transporting data in and out of it.
Interacts with online clients, keeping a reduced size of data in transport, with a shared and limited bandwith, the operations are most of all continuous reading over small sets of data, combined with some maintenance & CRUD operations.
Bigger data processing is done in batch, but the architecture is the same.
But a different scenario ?
What happens if we need to process 1 petabyte/week ?, let's say a much lesser size, 1 terabyte/day, less, 100 gigabytes/day
Under the traditional schema, it would be like moving an elephant over a string thousands of times, the time-windows would not allow to work with realtime information, but always trying to keep up and losing the race.
Want problems ?
The network would saturate, batch processes would take days to finish information of hours, the harddisk latency access it will transform into an incremental overhead, having a painful impact on overall costs.
The traditional approach would mantain the architecture, but changing hardware, sophisticated requirements, each time more expensive, bigger, but over a limited growth architecture. How many times will you change your system's architecture to non-linear scalar solutions to keep up with the race of growing data, ?
The solution is in the focus !
Problem 1: Size of data
systems handling public data, can have huge processing flows with hundreds of terabytes, public websites have had increased their data up to petabytes !
Strategy 1: Distribute and paralellize the processing
If chewing 200 Tb of data takes 11 days in 1 computer, let divide the whole process into as many machines needed to finish the task in minutes or hours !
If we'll have lot of computers, so be they cheap and easily mantained !, into a simple add & replace node architecture.
Problem 2: Continuous failure and cluster growth
In a big cluster, lot of machines fail everyday, besides the cluster size cannot be fixed and sometimes cannot be planned, it should grow easily at the speed of data.
Strategy 2: High fault tolerance and high scalability
Any design must have an excelent fault-tolerance mechanism, a very flexible maintenance, and its service availability should keep up naturally to its cluster size.
So we need a distributed storage, atomic, transactional, with perfect linear scalability.
Problem 3: Exponential overhead in data transport
From data source to its processing location, bad harddisk latency and saturated networks will end up exploting
Strategy 3: Move application logic to data storage
It must allow to handle data and processes separately and in a transparent way, applications should take care of their own business application code, and the platform should automatically deploy it into the datastorage, execute and handle their results,
So...
- Distribute and Paralellize processing
- High fault-tolerance mechanism, High scalability
- Take application processes to data storage
One Solution: Hadoop Distributed Filesystem + Hadoop MapReduce
Anyway, Hadoop is not bullet-proof, actually, it's a very specific solution for some big-data scenarios, with needs of realtime processing, and technology choices for random access to data. (See HBase, Hive)
Hadoop is not designed to replace RDBMS, but instead, has been proven to handle -in a much performant way- huge amounts of data, whereas traditional enterprise database clusters, wouldn't work not even close at the same overall costs !
Thursday, October 14, 2010
The platform
Hadoop commonly refers to the main component of the platform, the one from where the others offer high level services. This's the storage framework with the processing framework, formed by the Hadoop Distributed Filesystem library, the MapReduce library, and a core library, all working together. This represents the first project, that would lead the path for the others to work.
Those are: HBase (a columnar database), Hive (a data mining tool), Pig (scripting), Chuckwa (log analysis), they are all subjected to the availability of the platform. Then we have ZooKeeper (coordination service) independent of hadoop availability and used from HBase, and Avro (serialization/deserialization) designed to support the main service component requirements. We'll see them all after, in more detail.
I draw them in different layers, showing their functional dependencies and a little description for each component
(Click the picture to enlarge it)

Basic flow: how does it work ?
A Hadoop cluster compounds of any # of slave nodes, 1 master node managing them all, and 1 backup node assisting him.
The slave ones are data nodes which runs 2 processes: the DataNode process and the TaskTracker process. On the master node runs the NameNode process, and in other different node -whereas possible though not mandatory-, running the BackupNode process.
So, in practice the platform deploys in the cluster to 5 different processes, the NameNode, DataNode and BackupNode from the storage framework (HDFS), and the JobTracker and TaskTracker from the processing framework (MapReduce). In HDFS, The NameNode will coordinate almost all read/write and access operations between clients and the DataNodes from the cluster, the DataNodes will store, read and write the information, while the BackupNode is in charge of accelerating some heavy operations like boot up, ensuring failover data recovery, among others. In MapReduce, the JobTracker will coordinate all about deploying application tasks over the DataNodes, as well as summarizing their results, and the TaskTracker processes running on them will receive these tasks and execute them.
See in this diagram, how they're distributed within the flow.
(Click the picture to enlarge it)

Hadoop commonly refers to the main component of the platform, the one from where the others offer high level services. This's the storage framework with the processing framework, formed by the Hadoop Distributed Filesystem library, the MapReduce library, and a core library, all working together. This represents the first project, that would lead the path for the others to work.
Those are: HBase (a columnar database), Hive (a data mining tool), Pig (scripting), Chuckwa (log analysis), they are all subjected to the availability of the platform. Then we have ZooKeeper (coordination service) independent of hadoop availability and used from HBase, and Avro (serialization/deserialization) designed to support the main service component requirements. We'll see them all after, in more detail.
I draw them in different layers, showing their functional dependencies and a little description for each component
(Click the picture to enlarge it)

Basic flow: how does it work ?
A Hadoop cluster compounds of any # of slave nodes, 1 master node managing them all, and 1 backup node assisting him.
The slave ones are data nodes which runs 2 processes: the DataNode process and the TaskTracker process. On the master node runs the NameNode process, and in other different node -whereas possible though not mandatory-, running the BackupNode process.
So, in practice the platform deploys in the cluster to 5 different processes, the NameNode, DataNode and BackupNode from the storage framework (HDFS), and the JobTracker and TaskTracker from the processing framework (MapReduce). In HDFS, The NameNode will coordinate almost all read/write and access operations between clients and the DataNodes from the cluster, the DataNodes will store, read and write the information, while the BackupNode is in charge of accelerating some heavy operations like boot up, ensuring failover data recovery, among others. In MapReduce, the JobTracker will coordinate all about deploying application tasks over the DataNodes, as well as summarizing their results, and the TaskTracker processes running on them will receive these tasks and execute them.
See in this diagram, how they're distributed within the flow.
(Click the picture to enlarge it)

Tuesday, September 28, 2010
Who’s who
All three tools’s queries or sentences, from Hive, HBase & Pig, they compile to MapReduce collection jobs, they handle their design and weaving as well as their results and internalization, they expect to Save You Time, plenty of headaches, as avoiding code-scattering, highly coupled functions, that you can step into if you have to design complex chaining jobs, sharing states of information, or your own database tool, by only writing Java jobs implementing MapReduce contracts.
Instead, you can use them for the different purposes they were designed for.
Pig is recomended for chewing and manipulating some semi-structured data, also for discovering, parsing, etc. It also has some primitive collection datatypes, and Zebra works integrated with him as a simple database facility, to avoid unnecesary custom data persistance mechanisms.
For Hive and HBase you’ll need the data well structured and clean, do not even think about using them with raw data.
This’s one possible scenario, where varying several sources of data, in different formats or maturity levels, may convey into the hadoop distributed filesystem, where is it chewed by custom jobs or scripts. Then, it may be used as structured information, for later higher level purposes.
(Click to enlarge)

So, you’ll have to balance depending of your requirements, between faster but too simple logical tasks in MapReduce (chaining them will be a pronostic), and less faster but easier evolving design with clean code using Hive Queries or HBase methods. Sometimes you wont have to decide, write Java code in an MR approach may be a nightmare, you may end up writing too many simple routines hiding the real business purpose of their existance.
Still, although Pig is one of the most used methods for processing data, MapReduce is also commonly used for it’s simplicity, performance, and because it’s the base of a programming paradigm to sinthetize vast data into the information we need to get. Sometimes too, huge sizes of data are required to process for very simple tasks, and you wont need to prepare for a database design or strategy using Hive or HBase, etc.
A Markitecture
I want to show here a MapReduce-HDFS projects centered architecture platform. I left ZooKeeper out of this picture cause it’s not integrated to MapReduce nor HDFS, but only used by Hbase, the same with Avro that’s rather a backend library used by the core.
A Resume how they all interact, which languages they use, how the platform deploys their processes
(Click to enlarge)

I’ll be posting individual diagrams for them all.
Tuesday, August 24, 2010
Apache Hadoop is a family of projects focusing the big-data ambient concerns, with a paralell distributed computing strategy.
Tools from storing, processing, transformation, mining, analysis, searching, from big enterprise clusters up to university labs with some dozens of computers.
When it comes the time to evaluate this platform, it's unavoidable to compare it with other ones, and far from staring at the hurdles of research, training or implementation of any opensource-like software, we realize the day-to-day challenges and requirements this platform was born to handle, and the way that accomplishes its objectives. If you get involved in the matter, you'll find combination of challenges that no typical database tools were, already before, required to approach.
Why is it becoming widespreadly used, it's all about vision. The key of Hadoop main strategy is to masively scale only thru increasing amount of nodes, into a simple network architecture, generally composed of comodity hardware, common computers, no sophisticated datacenter hardware, diversity of comodity machines, so one important factor is to be prepared for malfunction, disconnection, of typical and common manufacture on all its peripherals, hardisks, switches, network boards, and so on.
In contrast to other enterprise database software products, requiring sophisticated hardware, maintenance, and most of all: high-budget contracts, for software and hardware, Hadoop takes advantage of the full potential of each node in the cluster, by distributing the data processing to all its nodes capacity, guaranteeing no exponential overhead, and so almost perfect linear scalability.
In order to match this strategy, other tactic is pursued: bring the processes to the data nodes, rather than transporting pieces of data went and back to the processing machines, this is a core concept of the platform design, and the key value of all its architecture.
The need of this vision, it's based on a data cluster growing masively non-stop every day. Beside public or statal organizations and companies, there're other new organizations allocating not only big amounts of data, but also at huge growing rates, these are websites, dealing with thousands or millions of users worldwide, and its proportional content generation, keeping the access and process results of this size of data in optimal performance. That's the context where the core design of Hadoop born, by the hands of an ex-Yahoo: Doug Cutting.
Inspired in Google's data infrastructure strategies, published a few years ago.
Yahoo got interested in Hadoop, then fully supported it. After some years, Hadoop took a greater and higher horizon, thru the open source community, making his author lead its evolution to advanced purposes than those inside Yahoo. (As stated publicly)
Tools from storing, processing, transformation, mining, analysis, searching, from big enterprise clusters up to university labs with some dozens of computers.
When it comes the time to evaluate this platform, it's unavoidable to compare it with other ones, and far from staring at the hurdles of research, training or implementation of any opensource-like software, we realize the day-to-day challenges and requirements this platform was born to handle, and the way that accomplishes its objectives. If you get involved in the matter, you'll find combination of challenges that no typical database tools were, already before, required to approach.
Why is it becoming widespreadly used, it's all about vision. The key of Hadoop main strategy is to masively scale only thru increasing amount of nodes, into a simple network architecture, generally composed of comodity hardware, common computers, no sophisticated datacenter hardware, diversity of comodity machines, so one important factor is to be prepared for malfunction, disconnection, of typical and common manufacture on all its peripherals, hardisks, switches, network boards, and so on.
In contrast to other enterprise database software products, requiring sophisticated hardware, maintenance, and most of all: high-budget contracts, for software and hardware, Hadoop takes advantage of the full potential of each node in the cluster, by distributing the data processing to all its nodes capacity, guaranteeing no exponential overhead, and so almost perfect linear scalability.
In order to match this strategy, other tactic is pursued: bring the processes to the data nodes, rather than transporting pieces of data went and back to the processing machines, this is a core concept of the platform design, and the key value of all its architecture.
The need of this vision, it's based on a data cluster growing masively non-stop every day. Beside public or statal organizations and companies, there're other new organizations allocating not only big amounts of data, but also at huge growing rates, these are websites, dealing with thousands or millions of users worldwide, and its proportional content generation, keeping the access and process results of this size of data in optimal performance. That's the context where the core design of Hadoop born, by the hands of an ex-Yahoo: Doug Cutting.
Inspired in Google's data infrastructure strategies, published a few years ago.
Yahoo got interested in Hadoop, then fully supported it. After some years, Hadoop took a greater and higher horizon, thru the open source community, making his author lead its evolution to advanced purposes than those inside Yahoo. (As stated publicly)
Subscribe to:
Comments (Atom)