Wednesday, November 17, 2010
Let's explore the core of the platform
Here are some relevant points about the filesystem
- Scales linearly over a set of low-budget comodity machines, doubled the amount of machines = reduced the processing time to half
- Tolerates faults at different levels, from network, switches, disks, nodes, readdressing data traffic to other nodes, accomplishing a replica factor
- Flexible scalability, for maintenance tasks, you only have to dis/connect computers into the rack
- Lets you allocate any kind of files and formats, although it has better performance on files bigger than 128mb
- The results of MapReduce jobs are stored in the filesystem
- There's a unique namespace, with an automatic replication schema administered by the master, it's not possible to impact on a certain node in the cluster, whether to allocate files or execute jobs
- The master itself balances the workload over execution plans and status reports from the slave nodes
(Click to enlarge)

{kind=link}
- Has a mechanism of continuous replication per file, rack-aware, to extend data reliability and data availability warranties
- Has an automatic file checksum with inmediate correction
- Works in a master-slave schema where slaves share nothing between them, they only respond to master requests
- The master coordinates all types of transactions, read/write, replication, restore, manages the tx log and the filesystem namespace
- The slaves only take charge on low level operations over data, read, write, deletion, transport to-from client
Main characteristics of Map Reduce
- It's a processing model about dividing and distributing information, in two chained phases: map first, then reduce
- Both phases have as input and output, a key-value pair list,
- The schema allows to define method parameters and own logic for both phases, as well as their own partitioning system and intermediate storage between phases.
- The transactions are handled by a JobTracker daemon, that runs the initial data partitioning and the intermediate data combination, by posting tasks of type Map and type Reduce over the TaskTracker daemons (1-n x computer) of the nodes involved in the cluster, according the data being processed
- the Reduce phase only starts when finished the Map, cause after the Map the resulting keys are combined, to distribute a sorted list of key-value pairs between the Reducers, that can be matched at the end of them.
- The process is transactional, those map or reduce tasks not executed, (for data availability issues) will be reattempted a number of times, and then redistributed to other nodes.
(Click to enlarge)
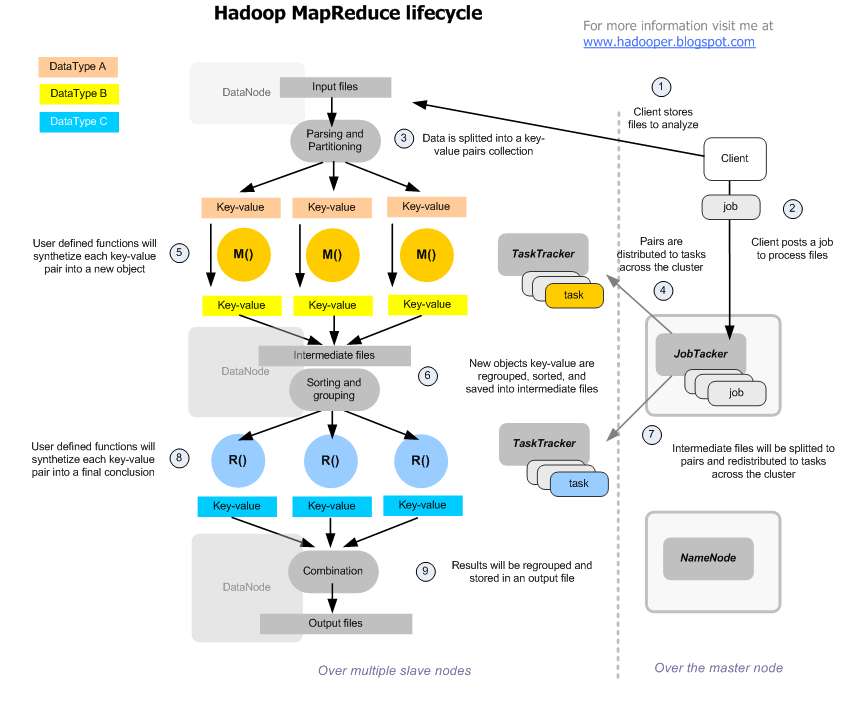
- First the files are partitioned in parts that will be distributed to process across the cluster nodes
- Each part is parsed in pairs of Key(sorteable object) - Value(object), that will be the input parameters for the tasks implementing the Map function
- These user defined tasks (map), will read the value object, do something with it, and then build a new key-value list that will be stored by the framework, in intermediate files.
- Once all the map tasks are finished, it means that the whole data to process was completely read, and reordered into this mapreduce model of key-value paris.
- These intermediate key-value results are combined, resulting a new paris of key-value that will be the input for the next reduce tasks
- These user defined tasks (reduce), will read the value object, do something with it, and then produce the 3rd and last list of key-value pairs, that the framework will combine, and regroup into a final result.
Let's see a sample job with a reverted-index function, for analyzing the webcrawler's output files (just for instance)
(Click to enlarge)

{kind=link}
Subscribe to:
Post Comments (Atom)
217 comentarios:
«Oldest ‹Older 201 – 217 of 217 Newer› Newest»-
delfen
said...
-
-
October 28, 2020 at 6:18 AM

-
Aptron Delhi
said...
-
-
November 23, 2020 at 7:58 AM

-
dataanalyticscourse
said...
-
-
December 3, 2020 at 6:35 AM

-
Unknown
said...
-
-
December 23, 2020 at 11:24 PM

-
jegan
said...
-
-
December 30, 2020 at 4:13 AM

-
Mr Eric
said...
-
-
February 25, 2021 at 5:06 AM

-
Buy Seo Service
said...
-
-
March 20, 2021 at 8:33 AM

-
Anonymous
said...
-
-
March 22, 2021 at 5:20 AM

-
rstrainings
said...
-
-
April 27, 2021 at 11:22 AM

-
Ravi Varma
said...
-
-
October 6, 2021 at 3:33 AM

-
Landmark Group India
said...
-
-
March 9, 2022 at 5:34 AM

-
Divya
said...
-
-
December 19, 2022 at 4:55 AM

-
priya
said...
-
-
January 9, 2023 at 6:50 AM

-
praveen
said...
-
-
March 1, 2023 at 9:30 AM

-
rathna priya
said...
-
-
April 7, 2023 at 2:48 AM

-
Digital Learning
said...
-
-
December 14, 2023 at 7:06 AM

-
vcube
said...
-
-
December 22, 2023 at 2:59 AM

«Oldest ‹Older 201 – 217 of 217 Newer› Newest»Thanks first of all for the useful info.
the idea in this article is quite different and innovative please update more.
waiting for more updates and content.
Data Science Training in Chennai
Data Science Training in Velachery
Data Science Training in Tambaram
Data Science Training in Porur
Data Science Training in Omr
Data Science Training in Annanagar
Android Institute in Delhi
need to thanks for the information seeks such more blogs with complete knowledge.
data analytics course
Thanks for sharing the informative post.
Machine Learning training in Pallikranai Chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
wonderful article contains lot of valuable information. Very interesting to read this article.I would like to thank you for the efforts you had made for writing this awesome article.
This article resolved my all queries.good luck an best wishes to the team members.learn digital marketing use these following link
Digital Marketing Course in Chennai
Awesome article, it was exceptionally helpful! I simply began in this and I'm becoming more acquainted with it better! Cheers, keep doing awesome!
Web Design Gloucester
Web Design Cheltenham
Web Design Company Gloucester
Local SEO Agency Gloucester
Thanks for such a wonderful content. Our Motive is not just to create links but to get them indexed as will
Increase Domain Authority (DA).We’re on a mission to increase DA PA of your domain
High Quality Backlink Building Service
Boost DA upto 15+ at cheapest
Boost DA upto 25+ at cheapest . Very Helpful
Very informative. Thanks for sharing.
Best Bike Taxi Service in Hyderabad
Best Software Service in Hyderabad
I am really happy to say it’s an interesting post to read . I learn new information from your article , you are doing a great job . Keep it up.
Thanks for sharing
+ COVID may stop you from coming out but not from growing up and moving ahead with your skills
this is really amazing, this article has a very good information which is very useful. thanks for it. Visit us for looking lands in Hyderabad Open Plots Near Sadasivpet Telangana
thank you for the blog.
Python Classes in Chennai
Python Classes Near Me
Best Python Training in Bangalore
Python Classes in Coimbatore
Digital marketing is creating brand awareness with the help of electronic media. It is a way of increasing digital awareness using electronic media such as phones, TV, and the internet.
Digital Marketing increases sales and builds customers' awareness of the product and services. Join the Digital Marketing Training in Chennai at FITA Academy to learn about digital marketing.Digital Marketing Training in Chennai
Digital Marketing Online Course
Digital Marketing Training in Bangalore
Nice blog, Share more like this.
Software Testing Course In Chennai
Software Testing Online Course
Software Testing Course In Coimbatore
Thanks for sharing the informative data. Keep sharing…
Swift Developer Course in Chennai
Learn Swift Online
Swift Training in Bangalore
thank you for sharing good information.In fuature i am expecting more information from your side.
AWS & DevopsTraining in Hyderabad
Wonderful information, thanks a lot for sharing kind of information. Your website gives the best and the most interesting information. Thanks!!
React-Js Training in Hyderabad
Post a Comment